As a content creator, finding the right hashtags to maximize the reach of your posts can be challenging. While popular hashtags like #car are easy to identify, discovering less saturated hashtags that can still drive engagement requires more effort.
To solve this problem, I developed a hashtag recommendation tool for my website, genius.social, which began as a simple toolbox for content creators (it envloved into another project that was killed by Meta, but that should be the subject of another article).
Here’s the story of how I built this tool, the technologies I used, and the lessons I learned along the way.
The Idea
The goal was straightforward: to help content creators find related hashtags with fewer posts that could enhance their reach.
The tool needed to scrape Instagram for hashtags, save the linkage between them (to create some kind of graph connecting all the hashtags), and provide recommendations based on this data.
This project involved several key components: a database to store hashtags and their relationships, a mechanism to scrape and save data, and a way to regularly update this information.
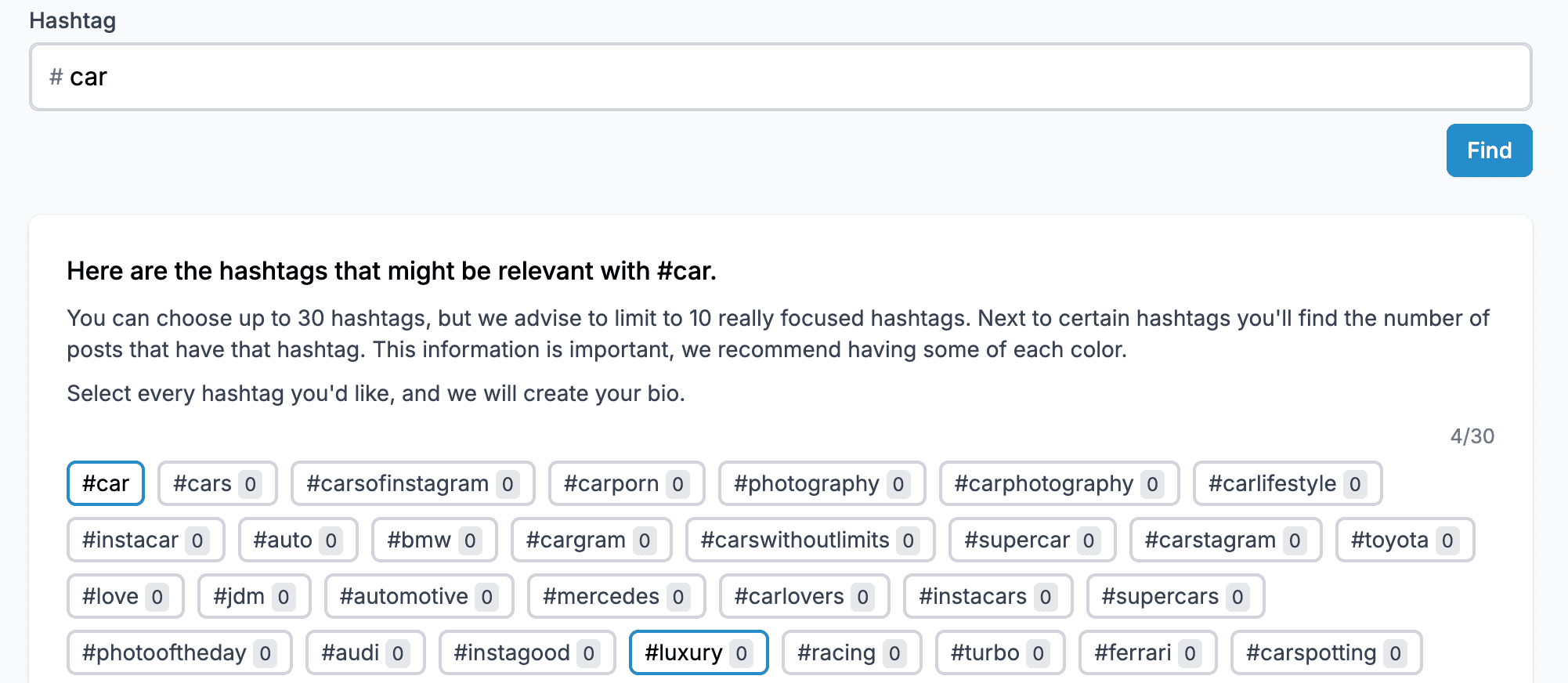
(The number next to each hashtag should be the number of posts containing that hashtags.)
Tech Stack
- Node.js: To handle the scraping of Instagram and the processing of data.
- AWS DynamoDB: For efficient storage and retrieval of the massive amount of data on hashtag linkages.
- AWS Lambda: To run the scraping process regularly without manual intervention.
- MySQL: To store metadata about hashtags, including the number of posts and whether a hashtag is banned.
- Next.js: For the front-end.
- ScrapingBee: Simplify the process of scraping Instagram, making data collection more straightforward and efficient.
Development Process
Scraping Instagram
Using Node.js, I wrote scripts to scrape Instagram posts for specific hashtags. For each post, the script would save all other hashtags used, creating a network of hashtag linkages.
For example if a post is using #car #bmw #carlover it would increment in the database the number of the realtion between car-bmw, car-carlover, bmw-carlover.
Database Design
I opted for AWS DynamoDB to handle the storage needs. DynamoDB’s ability to efficiently store and fetch large volumes of data made it ideal for this project.
The database structure included:
- A primary key (the first hashtag).
- A partition key (the second hashtag).
- A count of how many times this linkage was found.
Because of how querying a DynamoDB table works, I have to increment like if it was a directed graph. For example for the link between car and bmw, I have to perform 2 increments.
| pk | sk | count |
|---|---|---|
| car | bmw | +1 |
| car | carlover | +1 |
| bmw | car | +1 |
| bmw | carlover | +1 |
| carlover | car | +1 |
| carlover | bmw | +1 |
Automating the Process:
To ensure the data remained up-to-date, I used AWS Lambda to automate the scraping process.
Lambda functions were set to run at regular intervals, specifically triggered to update the oldest updated hashtag.
During each run, the function would take the latest posts containing that hashtag and grab all the hashtags used, then updating the linkage in the database as describe before.
Managing Costs
One of the biggest challenges was managing the costs associated with running the tool.
Scraping Instagram and storing large amounts of data in DynamoDB incurred significant expenses. The tool’s operational costs on AWS were higher than anticipated.
While DynamoDB and Lambda were efficient, the huge volume of data (over 70 million linkages) led to substantial AWS bills. I eventually had to pause the tool to manage expenses better.
Lessons Learned
Despite the challenges, the project was a valuable learning experience. Here are some key takeaways:
- Understanding cloud services: working with AWS services like DynamoDB and Lambda taught me a lot about cloud computing, scalability, and cost management.
- Database management: designing a database to handle large-scale data efficiently was a critical skill I developed. DynamoDB’s NoSQL approach required a different mindset compared to traditional relational databases. I’m still very impressed by DynamoDB’s performance, but achieving this performance requires a robust table design. For anyone looking to master DynamoDB, I highly recommend ‘The DynamoDB Book’ by Alex DeBrie. It’s an excellent resource for learning how to use DynamoDB effectively and understanding the importance of a well-structured table design.
- Automation: Implementing AWS Lambda functions for regular updates was a practical lesson in automation and serverless computing.
Conclusion
Building the hashtag recommendation tool for genius.social was a great journey. While the project is currently on hold due to cost constraints, the knowledge and skills I gained are invaluable.
I hope to revisit and refine this tool in the future, potentially exploring more cost-effective solutions. For now, I’m excited to share my experience and learnings through this blog post, hoping it can inspire and help others in their own projects.